- 인공지능 학습은 크게 머신러닝이 있고, 머신러닝으로 지도 학습, 비지도 학습, 강화학습 3종류가 있다.

강화학습의 특징
1. 강화학습에는 답을 알려주는 사람이 없고, 오직 보상 신호만 제공한다.
- 레이블(지도 학습)을 제공하는게 아닌, 목표만 정해주는 것임!
2. 피드백이 즉각적으로 제공되지 않고, 약간의 딜레이가 있을 수 있다.
- 내가 좋은 액션을 했을 때 바로 보상이 주어지지 않고 나중에 받을 수도 있다. (단점)
3. 시간이 중요하다. 연속적인 데이터를 제공받기 때문이다. (순서도 중요함)
4. 에이전트의 행동은 받게되는 데이터에 영향을 준다. 정해진 데이터 셋을 잘 정해줘야 한다.
보상이란?
- 보상은 무조건 스칼라 값이다.
- 에이전트가 얼마나 잘하고 있냐의 지표이다.
- 한 학습에서 보상 값들의 합이 최대가 되게 만드는게 목표다.
- 즉각적으로는 안좋을 수 있어도, 장기적으로 최선의 결과를 만들게 액션을 취하게 만들어야 한다.
에이전트와 환경
-observation
-action
에이전트가 액션을 하면 환경이 보상과 observation(관측값)을 준다. 그러면 에이전트는 이 값들을 받아서 다시 액션을 수행한다.
-reward
History and State
observation, action, reward를 진행하는 과정동안 계속 추적하는게 History(시간당 관측값, 행동, 보상을 추적)
State는 다음에 할 액션을 결정하기 위한 정보이다.
즉 environment state는 reward와 observation을 계산하기 위한 모든 정보들(상태)이다.
Agent state는 다음 행동을 하기 위한 모든 정보들이다.

State는 마르코프 상태로 고려할 것인지 확인해야함.(직전 상태만 보고 결정)
식을 보면, 조건부 확률, 현재 상태 St가 발생했을 때, St+1의 확률은, S1~St가 발생했을때 St+1의 확률을 구하는 것과 동일하다. 즉 직전의 상태만 고려해도 똑같다는 의미이다.
예시

- 쥐가 전구, 전구, 레버, 종을 골랐을 때는 감전,
종, 전구, 레버, 레버를 했을 땐 치즈를 받았다.
레버, 전구, 레버, 종을 하면 감전일까 치즈를 받을까?
우리가 설정해준 상태에 따라 다르다. 우리가 순서를 중심으로 생각하면 감전으로 예측되고, 각 전구, 레버, 종의 개수를 기준으로 판단해보면 치즈를 받는다고 예측할 수 있다.
4가지 선택의 상태를 완전한 순서를 중심으로 생각하면, 결과는 알 수 없다.
Fully Observable Environments
Observe state, environments state, agent state가 모두 동일한 것. 이걸 마르코르 결정 과정(MDP)라고 한다.
Partially Observable Enviornments
agent state, environments state가 서로 다름
예를들어, 로봇이 카메라를 달고 걸어간다면, 카메라의 시각 정보가 전부이다. 로봇의 위치정보를 알려주지는 못한다. Partially observable Markov decision process-POMDP(폼디피 라고 많이 부름)
에이전트의 상태는 히스토리를 사용하든, 신경망(rnn)을 사용하는 방법 등 사용가능
RL agent 구성요소
정책 - 에이전트의 행동을 정의, 상태 s가 들어오면 액션을 정해줌

가치 - 현재 state가 좋은지 안좋은지를 평가해줌
한 게임을 다 끝마칠때까지의 기댓값의 총 합이 Value Function이다.
환경 state는 예를들어 앞으로 가더라도, 바람 등의 이상한 요인(실제로는 없다고 가정하고 사용)들에 의해 앞으로 가는 행동을 했지만, 앞으로 가고 오른쪽으로 가질 수도 있다. 이러한 변수들을 다 고려하여 더하여 평균낸 값이, 기대값이다.
모델 - 환경이 어떻게 될지 예측하는 것
- 보상을 예측
- 상태 변화를 예측
예시

Start에서 Goal까지 가는게 목표, 보상은 한칸을 갈 때마다 -1을 받음(최대한 적은 칸을 이동하기 위해), 액션은 4가지, 상태는 에이전트의 위치이다.
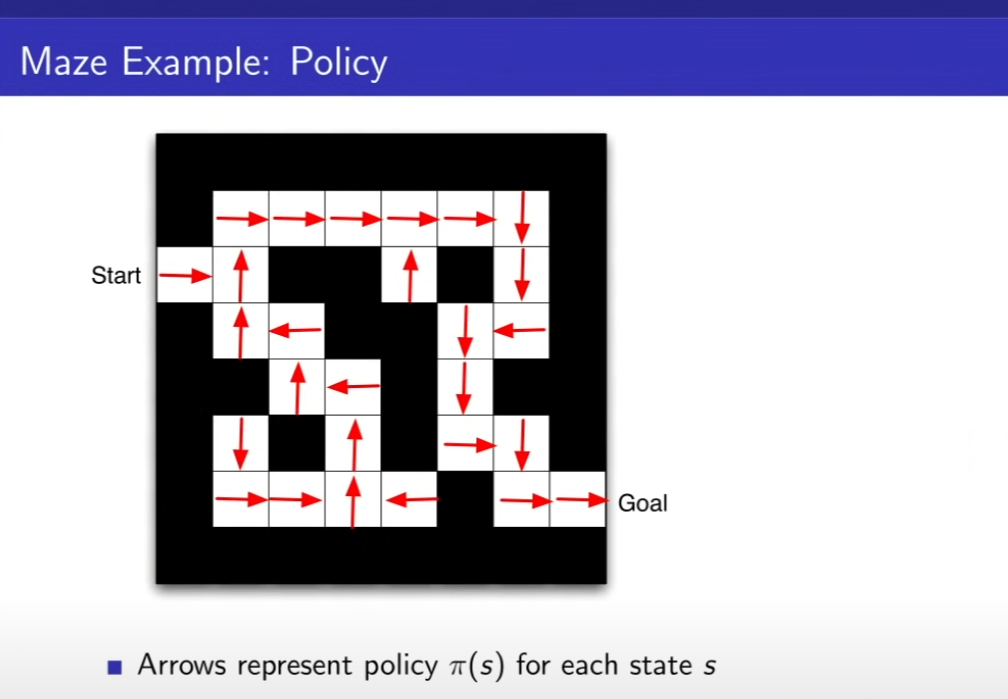
화살표는 각 칸에서의 최적의 정책을 나타내고 있다. state를 넣어줬을때 어떤 액션을 하느냐가 policy이다. 즉 화살표가 policy이다.

Value Function은 내가 받을 미래의 리워드 총합, 각 위치에서의 Policy를 따라 행동했을때 리워드 값이 적혀있다.
Policy가 있어야 Value Function을 정해줄 수 있다.

모델은 state가 어디로 가는지, 리워드가 몇인지를 알아야 한다. 환경 state가 아니라, 에이전트가 바라본 환경은 현재 그림과 같다는 것이다.
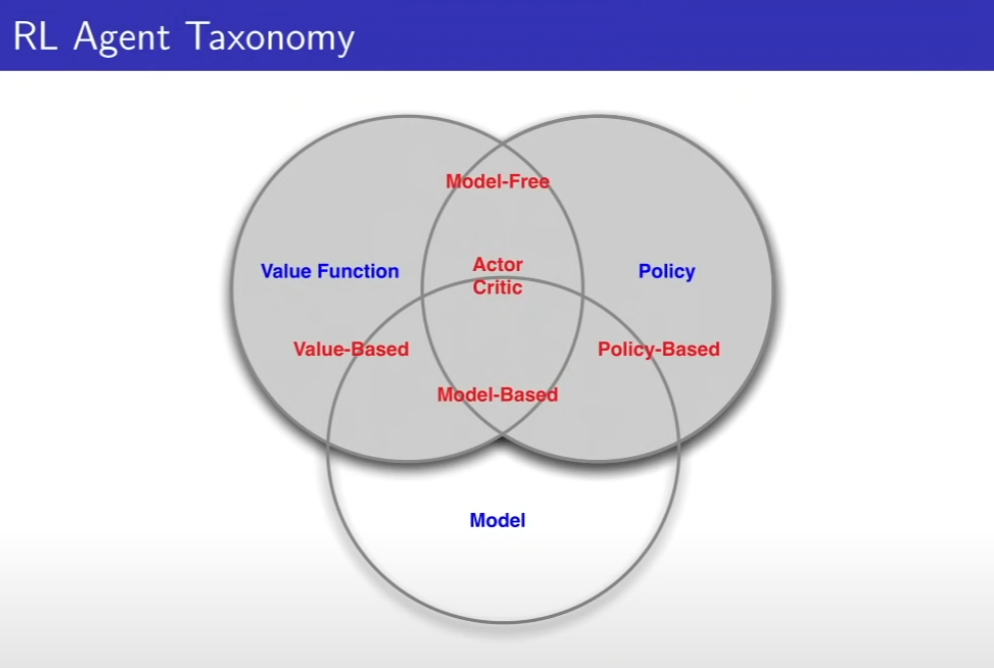
RL Agent 분류하기
-Value Base
Value Function만 있다. 정책이 없다. 좋은 위치를 알고 있다면, 거기로만 가면 된다.
- Policy Based
Policy만 있다. 가치 함수가 없다.
- Actor Critic
둘다 있다.
3가지 말고, 2가지로도 분류가 가능하다
- Model Free
모델을 만들지 않고, 정책과 가치함수만 있음
- Model Based
내부적으로 모델을 미리 만들어서, 모델을 기반으로 정책과 가치함수를 사용해 만듬
Prediction and Control
Prediction - 미래를 평가하는 것, 정책이 주어졌을 때 가치 함수를 구하는 것
Control - 미래를 최적화하는 정책을 찾는 것
'AI > 강화학습' 카테고리의 다른 글
| 1. [OpenAI] Spinning Up in Deep RL Introduction (1) | 2025.01.16 |
|---|---|
| Model Free Control (0) | 2024.06.25 |
| Model Free Prediction (0) | 2024.06.16 |
| Planning by Dynamic Programming (0) | 2024.06.15 |
| Markov Decsion Processes(MDP) (0) | 2024.05.12 |



